





お客様のビジネスに新たな可能性を見出す
アプリのリサーチ、開発、リリースから運用まで、あなたのニーズに応じたフルサイクルのシナリオ構築。
飛躍的な成長に向けて準備が整いました

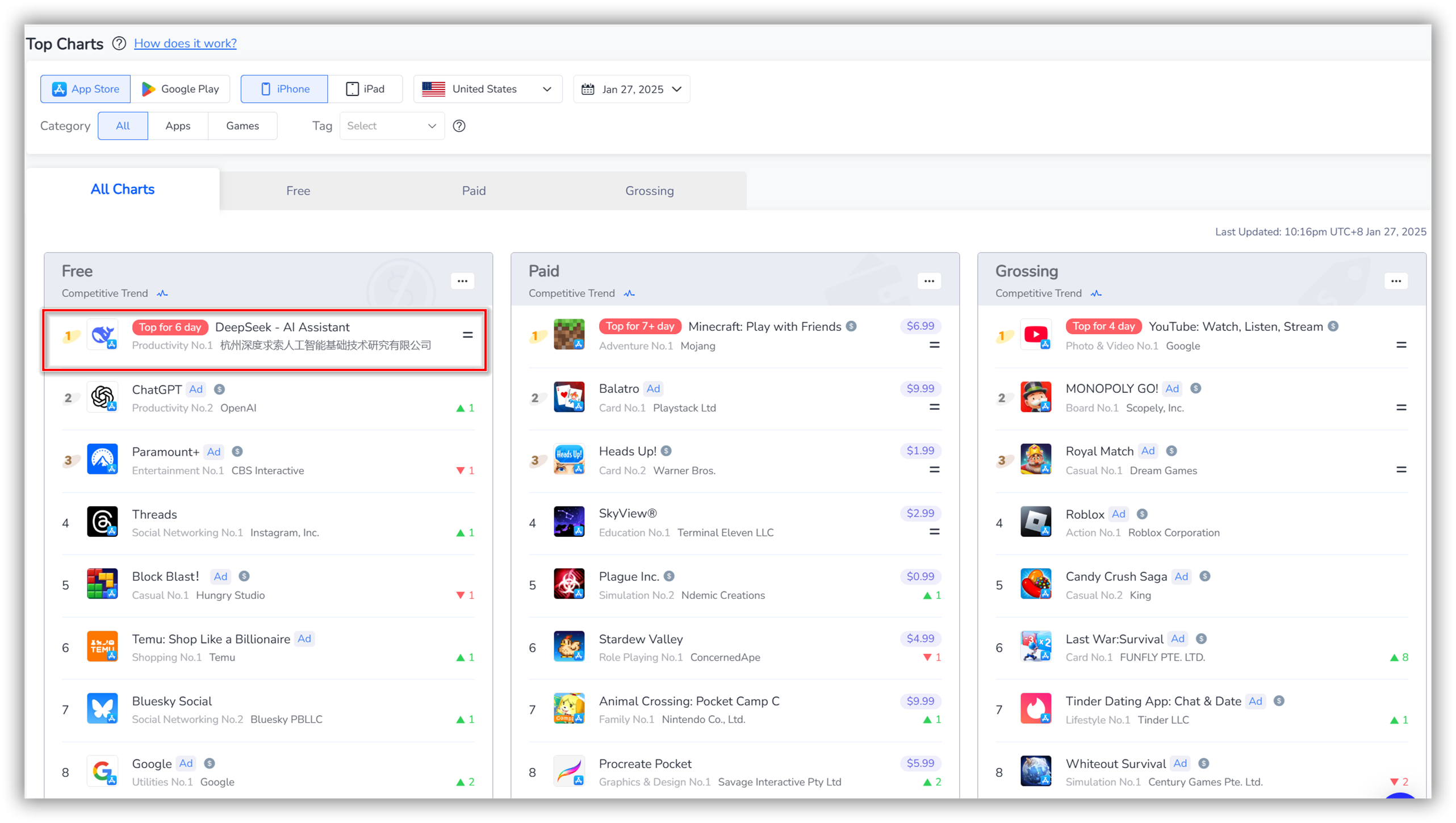

DeepSeek は、中国に拠点を置く比較的小規模な企業である High-Flyer が作成した一連のトランスフォーマー モデルです。このシリーズで最も有名なモデルは、DeepSeek V3 と DeepSeek R1 です。これらのモデルは、OpenAI の GPT や Meta の LLaMA などの他の大規模言語モデル (LLM) と共通の基礎技術を共有しています。ただし、いくつかの重要な革新によって他とは一線を画しています。
基本的に、DeepSeek モデルは Transformer ベースのニューラル ネットワークです。このモデルは、前の単語によって提供されるコンテキストを使用してシーケンス内の次の単語を予測することによって機能します。これは、携帯電話のテキスト予測の高度なバージョンに似ています。このテクノロジは、ChatGPT やその他の広く使用されている生成言語システムでも使用されています。DeepSeek モデルが他と異なるのは、効率性の向上、新しいトレーニング手法の導入、AI 開発へのよりオープンなアプローチです。
DeepSeek の基本情報とパフォーマンスの詳細については、ここをクリックしてください👉 アプリストアでの DeepSeek AI アプリのパフォーマンスはどうですか?

DeepSeekは創業以来、一貫して高性能なAI大規模モデルを発表してきました。2024年初頭、DeepSeekは初の大規模モデルであるDeepSeek LLMをリリースしました。このモデルは、670億のパラメータを活用し、2兆トークンのデータセットでトレーニングされ、優れた言語理解および生成能力を発揮しました。これに続いて、DeepSeek-V2モデルも注目すべき成功を収め、GPT-4 Turboに匹敵する優れたコスト効率とパフォーマンスを提供し、「AI界のPinduoduo」というニックネームを獲得しました。
2025年、DeepSeekは技術革新の先駆者として登場し、DeepSeek-R1などの効率的なアルゴリズムを搭載したさまざまなモデルを発表しました。強化学習を採用したこのモデルは、競合他社のわずか3%~5%のコストで、数学やコーディングなどの分野で優れたパフォーマンスを発揮しました。
これらの進歩は、DeepSeek の技術強化への注力と密接に関係しています。DeepSeek は、専門家の疎混合アーキテクチャを採用することで、アルゴリズムのアップグレードと計算能力の最適化を重視しています。さらに、適応型動的リソース割り当てによって計算効率を向上させ、実際のアプリケーションで堅牢な計算機能を保証します。
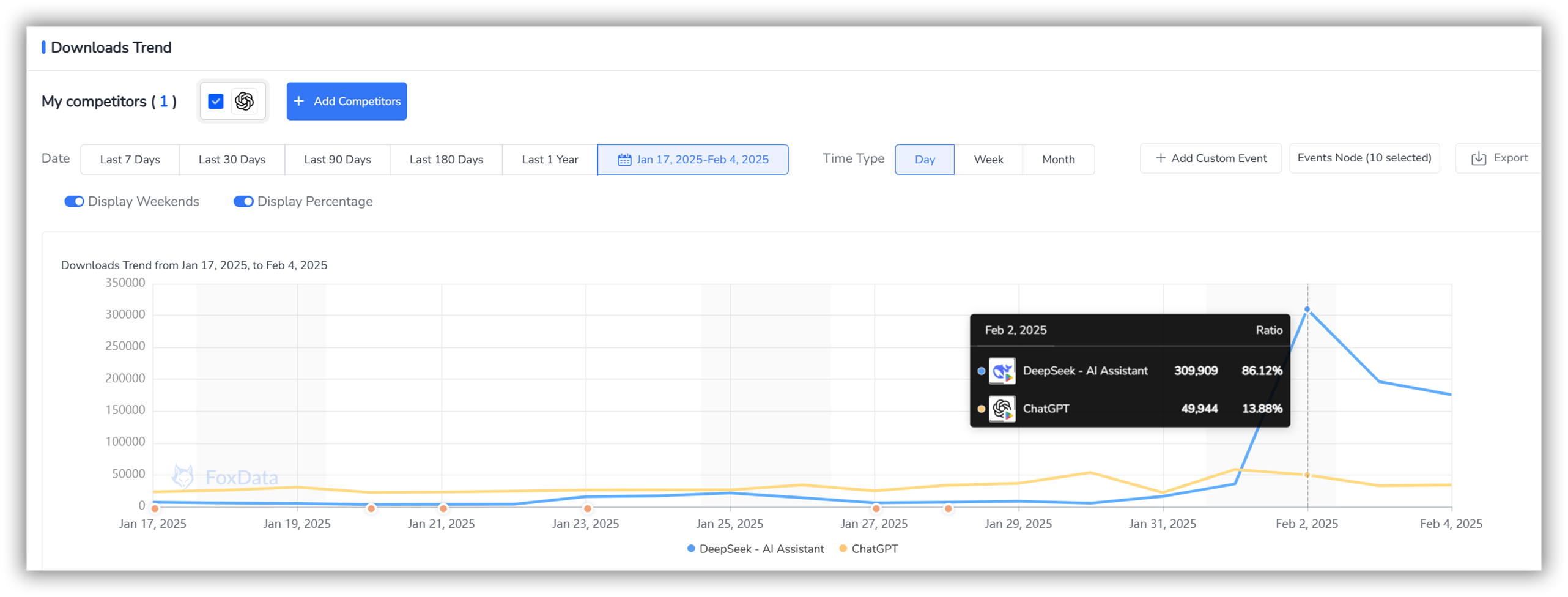
実際のアプリケーションにおいて、DeepSeek は市場に適応する成熟した能力を実証しました。
B2B 分野では、DeepSeek は金融、政府、製造業などさまざまな業界に効率的なソリューションを提供しています。
消費者市場では、DeepSeek は急速に人気を博し、日常生活におけるインテリジェントなアシスタントとなりました。学習支援、感情サポート、創造性の刺激など、DeepSeek はユーザーのニーズを総合的に満たし、肯定的なフィードバックを得ています。
DeepSeek の価格戦略も大きな利点の 1 つです。
同社の API サービスは OpenAI の 3 分の 1 の料金と非常にリーズナブルなため、中小企業や個人開発者にとって利用しやすいものとなっています。
さらに、DeepSeek はオープンソース戦略を採用しており、開発者からの幅広い参加と貢献を促し、堅牢な技術開発エコシステムを育成しています。
DeepSeek の際立った特徴は、オープン性へのこだわりです。OpenAI などの企業がモデルやトレーニング方法を秘密にしていることが多いのに対し、DeepSeek はモデルとコードを一般に公開しています。この透明性は、一般的に秘密主義が特徴の業界に新鮮な変化をもたらします。
DeepSeek は、モデルをアクセス可能にすることで、競争の公平性に貢献しています。小規模な組織や個人の研究者は、膨大な計算リソースを必要とせずに、これらのモデルを試したり強化したりする機会を得られます。このアプローチは、イノベーションを加速させる準備ができています。
👉AI 市場の洞察とトレンドをもっと読む。
将来の AI の成功を解き放ちましょう! 独占的な洞察を得るにはフォローしてください! 🎮
当社のサービスのパワーを体験してみませんか? 今すぐ無料トライアルにご登録ください! 🕹
© 2020-2026 FoxData. All Rights Reserved.
